My Portfolio of Projects
First posted: 9th February 2022Last update: 16th October March 2022, updated continuously
Introduction
I like to work on a wide variety of different things, because I am generally rather easy to excite ;-). For this reason, I have worked on quite a few hobby projects over time. On this page, I want to present a selection of some of them which I find particularly interesting or cool.
Larger Projects
1. Analysing the Correspondence between Goethe and Schiller: a NLP Data Science Project
Here, you can find the complete source code for this project of mine, where I have webscraped, preprocessed, analysed, and visualised the complete correspondence between the two famous German poets Goethe and Schiller. This was the first time I worked with natural language data, and the first time I did linguistic corpus analyses. I especially enjoyed working "from start to finish", beginning with the messy raw data and going all the way to the visual presentation of the results.

2. YACD: A Covid Dashboard for Germany, deployed on Heroku
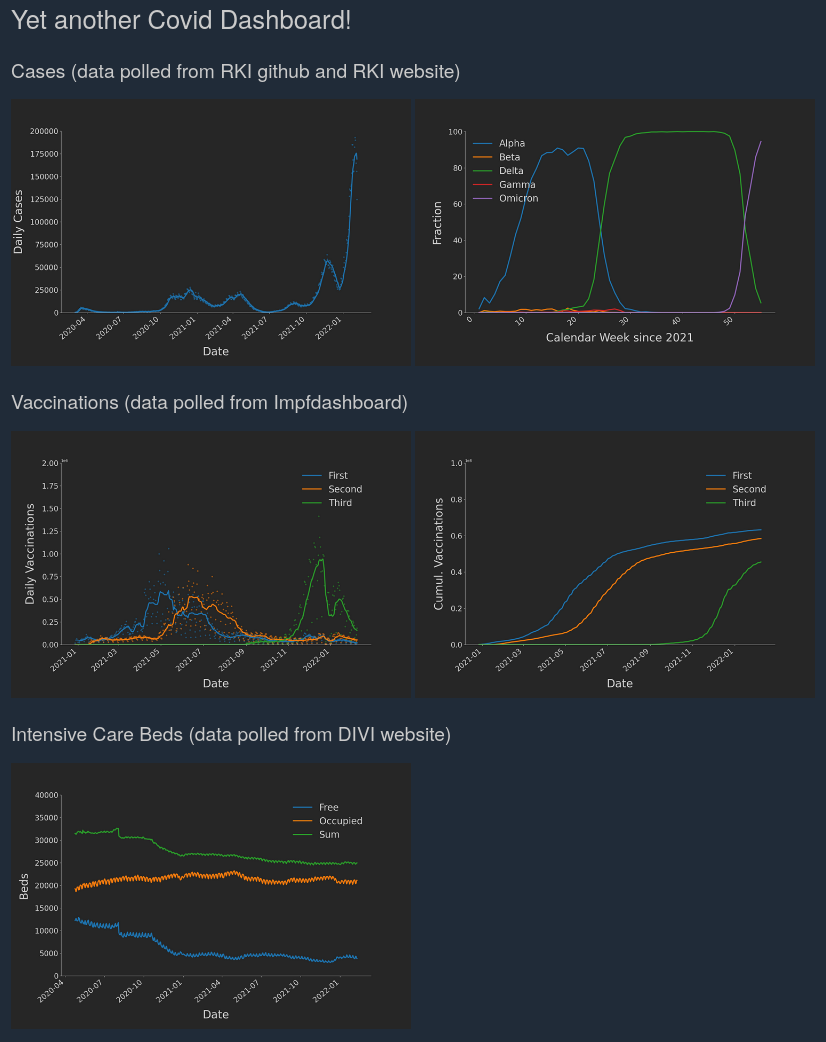
A web app in Python using the flask library. It loads data on the Covid pandemic from different web sources, processes them, generates plots, and serves those as a HTML dashboard to the web. It is deployed on the cloud application platform Heroku, which is something I have never used before, but continue to be amazed by. For the source code, check out this repository, and for the three-part writeup of the project refer to these three blogposts.
3. yaptool: "Yet another plotting tool"
A blog post for this project is not yet available, since it is still a bit WIP-y, but you can find the latest version of the source code in this repo. It's a library that consists mostly of wrapper functions around the matplotlib library for Python. Its main purpose is the reduction of boilerplate code required for day-to-day tasks, as well as providing some aesthetically pleasing default parameter choices. I dogfood it in my daily work, hence it is under continuous development.
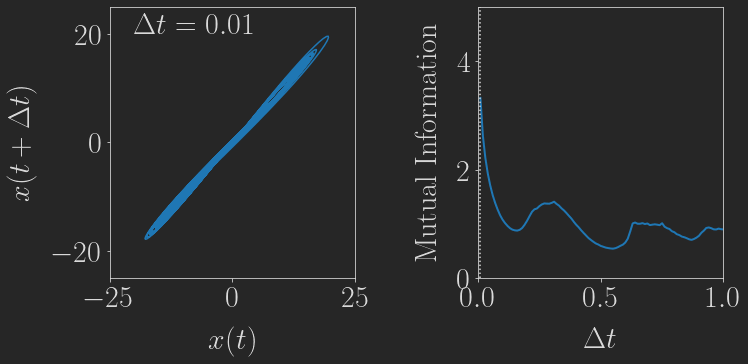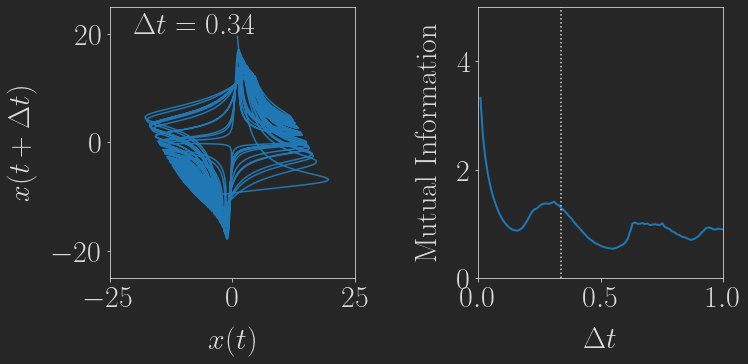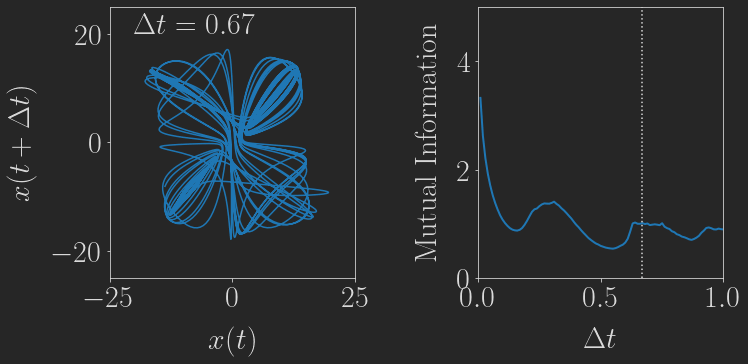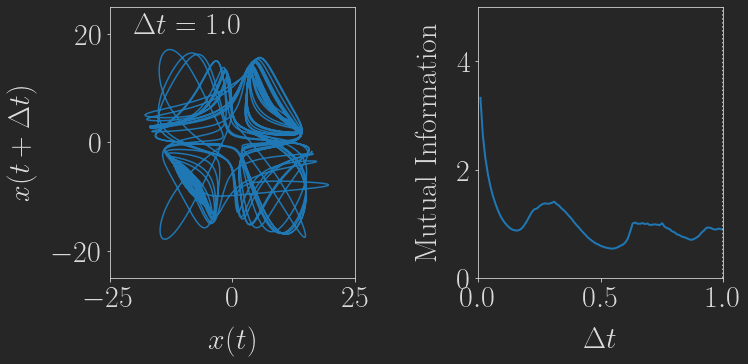
Smaller Projects
1. Automatically querying NCBI's pubmed Database of Scientific Papers
In this github repository, you can find a tiny Python file providing a function to track how often a certain keyword appears in the biomedical research literature over the years. I have used this function to generate all the data for this blog post of mine, in which I have analysed how the frequencies of certain keywords rises and falls over the years.

2. The Ancient Rite of Passage: My own Memory Manager
Going back to my roots as a C nerd and low-level aficionado, I finally did what every advanced C programmer is recommended at some point of time: implementing an own memory manager in plain C from scratch. See here for the source code, this blog post for a high-level write-up, and this blog post for a follow-up where I compare the performance of different allocation strategies. Some further analyses are to come soon.
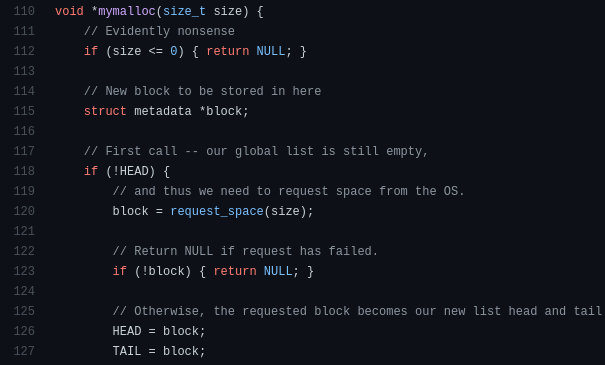
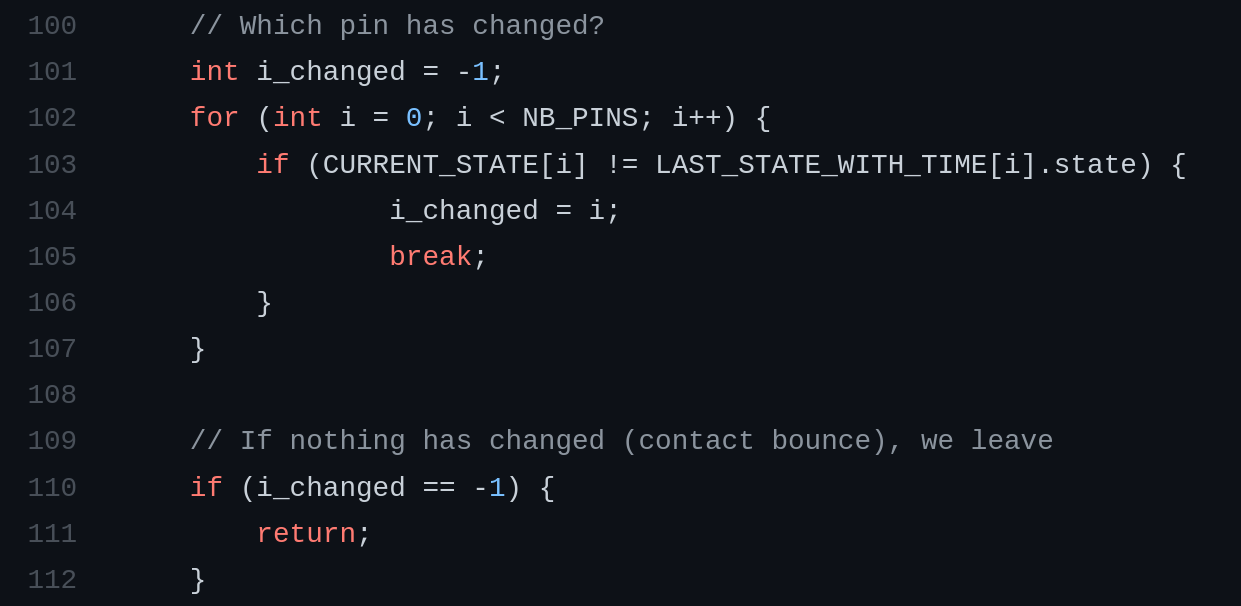
3. A Logger for the Raspberry Pi, written in C
More C nerdery: I wrote this little logging software for recording changes in GPIO pin states for the Raspberry Pi. Please refer to this blog post for the project's writeup.