The Ancient Rite of Passage, Part 2: Comparing Allocation Strategies
Posted: 13th March 2022Introduction
In the last post, I've implemented my own memory manager -- that is, I wrote my own versions of malloc(), calloc(), realloc(), and free() from scratch in C. The final implementation is now in the main.c of this github repository. My implementation is largely based upon this excellent tutorial, however I have added some improvements and extensions here and there.
In particular, the tutorial used a first-fit allocator. This means, when we are trying to allocate a block of memory, the allocator searches through the list of free memory blocks and returns the very first one of sufficient size it finds. In constrast, it's of course also imaginable to search through the complete list and return the block that fits the best. This can be expected to be slower, but is likely to not fragment the memory as much.
In my implementation, I have implemented both allocation strategies because I wanted to exactly quantify their difference with respect to execution time and memory fragmentation. Here, I present my results.
Approach
To compare the two allocators, I've written a little loop that randomly allocates memory blocks of random size and randomly deallocates randomly selected occupied blocks of memory. You can find the source code of the simulation in the performance_comparison.c of the project's github repository. In order to automatically simulate multiple different scenarios with different random seeds, the simulation takes some command-line arguments, so that we can execute it over and over again from within a shell script using with diffeferent initialisations.
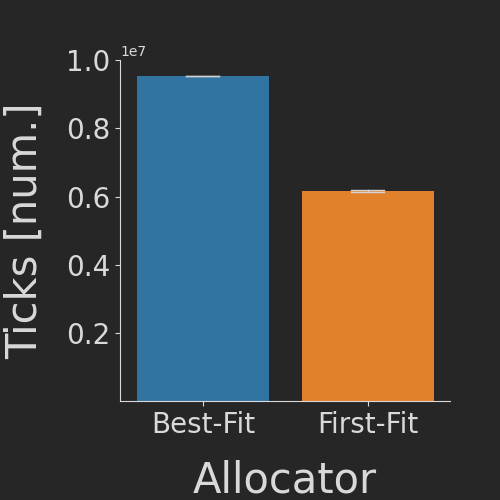
First-Fit Allocation is faster
First, we count the number of elapsed processor ticks for one million random simulation steps (i.e. random allocation or random deallocation). As expected, the first-fit allocator performs significantly faster as the best-fit one. (The tiny error bars are the standard deviation across 3 replicates each.)
Block Merging is more important than Allocation Strategy to reduce Fragmentation
Next, we assess how much the allocation strategies fragment the memory, i.e. lead to a high number of unused tiny blocks of memory which are likely to end up unused. As a very first metric to assess this, we simply calculate the mean size of all free blocks after again simulating one million random allocations and deallocations. We compare the results for two different scenarios: In the first scenario, when we deallocate a block of memory we don't try to merge it with its neighbours if those are free. This is the way the tutorial has implemented free(). In the second scenario, we allow for such a merging -- which was actually an exercise suggested by the tutorial. By re-using the same set of seeds, we can perform pairwise comparisons for these different configurations, increasing our power to detect statistically significant differences.
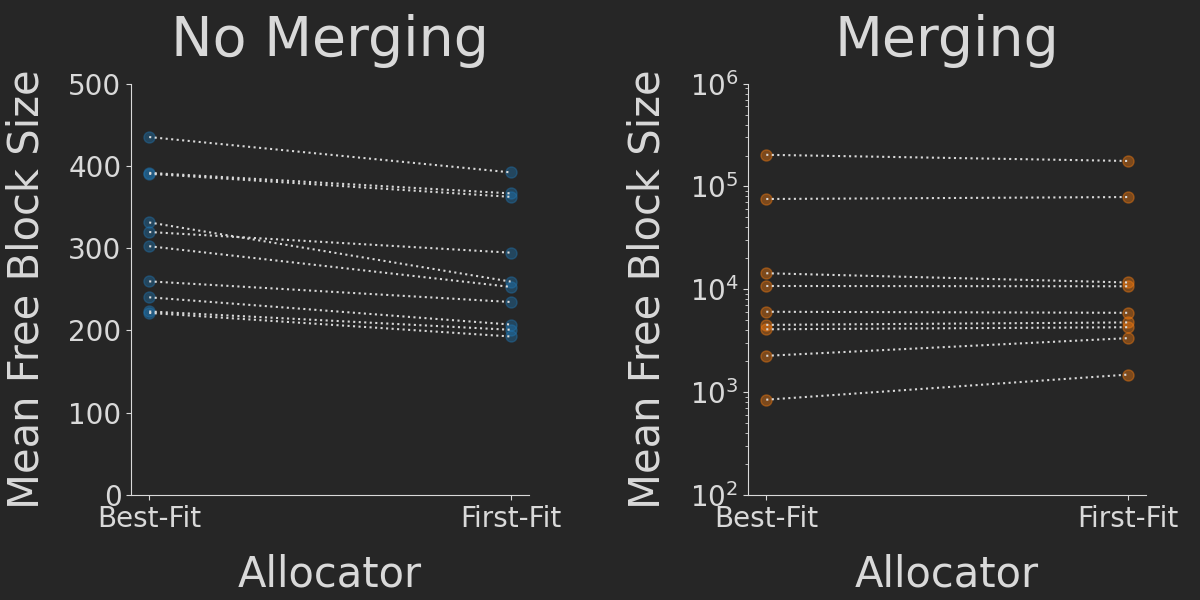
Multiple things can be seen here: For the case of no block merging (left plot), the first-fit allocator consistenly causes more memory fragmentation than the best-fit one, as expected. The effect, however, is rather small. In contrast, allowing for block merging (right plot) leads to no significant difference between the fragmentation.
In addition, allowing for block merging greatly increases (notice the vastly different y axis scales) the average size of free blocks by several orders of magnitude. Thus, allowing for block merging is way more important for securing unfragmented memory than using the right allocator.
Conclusions and Outlook
During my simulations, I repeatedly run into segfaults. Thus I reexamined the code and actually discovered two critical bugs which would cause the pointer structure of the doubly-linked list to become inconsistent under some circumstances. Importantly, I haven't found these bugs earlier while running some standard unit tests for my allocator. A friend of mine remarked that my simulation basically boiled down to a "fuzzing" of my allocator, which can be seen as a more thorough form of software testing and something I will definitely do in the future for other software projects.
Some more things could be tested and might be interesting:
- Comparing the execution time with vs. without free block merging. Allowing for block merging likely introduces a certain overhead, however as we have seen leads to less memory fragmentation.
- Compare specifically the time spend on allocating vs. deallocating, instead of just comparing overall execution time for the complete simulation.
- Look at other allocation strategies -- for instance, instead of first-fit, a second-fit strategy has been proposed in the past, which might be interesting to look into.